Rate Limiter
Scenario 1: * Consider you have an application which is deployed in a server, and then it is working fine and some day you started to see sudden increase in traffic, for ex: 10 times the normal traffic and all the traffic is from BOTS.
Scenario 2: * Consider you have a product which provides API for payment gateway , you want to restrict the user after 3 requests per day.
- For Both these scenarios the solution is rate limiting.
- Rate limiting products your APIs from overuse by limiting how often user can access your API.
- Once the users quota is finished either the requests are dropped or rejected, and it is very important for many important reasons
for example:
a) User Experience (UX): In the application some users are using overusing the API's in that case the other users will get affected. So if you maintain quality of service or better UX you need to rate limit.
b) Security: People might try brut forcing the login API's or some other API's like promo codes, you need to rate limit to protect the application attacked by the hackers.
c) Operational Cost: For example your application is enabled for auto-scaling or Pay as you go service. If the users are bombarding requests just for fun or by mistake, then the cost will increase.
Levels at which use can Rate Limit or Types of Rate Limiting
- User : how many requests you are going to allow for a user for one min or a certain duration.
- Concurrent : For a given user how many parallel sessions or parallel connection is allowed.The main at advantage is to mitigate the DDOS attack.
- Location Id : You are running a campaign dedicated to that location. you can rate limit all the other locations.In that way you can provide high quality of service for the location which you to target.
- Server : This is a weired case, but it might come handy on certain kind of situations where you have defined a server is dedicated for certain kind of service in which you can rate limit different services the server provides that way it will help you to enforce some kind of rule on serve rate.
Algorithms For Rate Limit
a)Token Bucket : Suppose we are limiting our API's to 5 requests/min .
- We can use redis as the token bucket because it is in memory and faster to access.
- For every unique user we will track the last time at which the request was made and the available tokens. U1 : 12:04:01 5
- So every time when the request comes in the rate limiter should do 2 things
- Fetch Token
- Update Token : once it access the token, and understood that we have enough token left so it can make the request and also afterwards it should update the token to the latest token available
- U1 12:04:25 then the available tokens will be 5 , as the new request is made the token will be updated to 4.
- U1 12:04:37 then the token will be reduced to 3.
- U1 12:07:07 and the token is refilled to 5 as this is the new minute,then the token will be reduced to 4.
- If all 5 tokens are completed , if the new request comes in the same minute then the request will be dropped.
- This algorithm is memory efficient as we are saving less amount of data per user.
- But in distributed environment it could cause race around condition i.e 2 requests are coming from 2 app servers for the same user, so both will try to update the token and the time.
b)Leaky Bucket :
- Consider you have bucket which can hold 3 requests at any given point of time
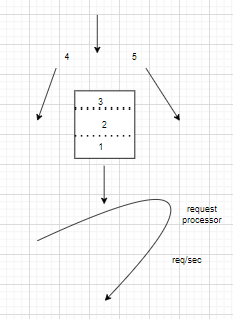
- Whenever the requests are coming into the bucket it will sit into the bucket and from there to the request processor.
- If more requests are coming in the bucket will fill immediately before even we process it.
- And the extra requests like 4 , 5 requests will overflow.
- If the first request is processed , so we have some space in the bucket , so we can accommodate a new request in the bucket.
c) Fixed Window Counter
- This is the simplest of all .
- Here, we will have a counter we keep on incrementing the counter for every request and when the counter exceeds the rate limit we are going to drop all the requests which are coming in.
- For example, we have defined 10R/M.
- We can use Redis, for storing the time as key and value as the counter value. U1_11:00 10 U1_11:01 0
- It is memory efficient.
- But there is one more problem
- Suppose we got more requests at the end of the minute, then the server is overloaded and also the traffic is not smoothened.
d) Sliding Logs
- We can use either hash table or redis.
- U1 : [0 0 0 0 0 0 0 0] each entry should also contain timestamp.
- We need access the array and then filter out all the entries older than one minute.
- The problem is we need to store as many entries which is almost equal to the rate limit (1OR/min).
- If we have a million users then 1M*rate limit , that much data in redis/hash table is bad.
e) Sliding Windows Counter
- This is similar to sliding logs but we need to optimize in case of memory.
- UI:[11:30:01 2 11:30:02 5 11:30:05 3 ] 11:30:01 11:30:01
- For each and every request also we need to sort and filter out entries from the last minute amd then count the values i.e 2+5+3 = 10
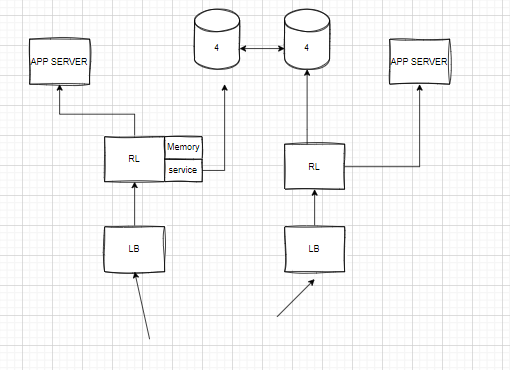
Distributed
- All the Above algorithms only on the single server. But we have distributed setup with multiple servers we will face 2 problems a) Inconsistency in the rate limit data. b) Race condition (locks)
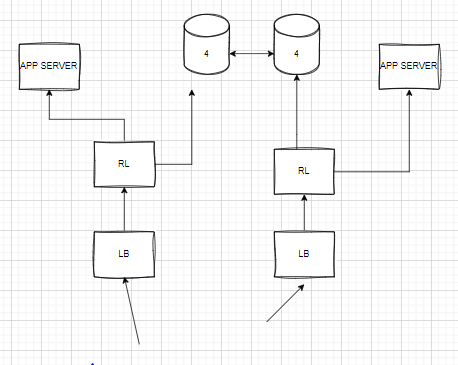
- We can solve this problem by sticky session.
- We should redirect the user to the same load balancer.
-
This is not a well-balanced design, because if all the requests from one users goes to the same app server and rate limiter, the load on the server will increase.
-
If more than one rate limiter is available, then one rate limiter is access the value from the redis then it will put lock on that key.
- so that no other limiters will update the count. But it will add some latency.
- we can solve this by a) Relaxing rate limit b) Local Memory + sync service.